There are plenty of times when I want to talk about a project without handing over the whole repo.
Sometimes I want a second opinion on architecture. Sometimes I want to plan a
feature before opening the repository to a coding agent. Sometimes I want to ask
why a project is shaped a certain way, but I do not want to paste the README,
AGENTS.md, package manifests, docs, and a dozen old decisions into a chat.
This is one of the directions I care about for Memory: let a ChatGPT-style assistant talk to the project through durable memory instead of broad source access by default.
The local Memory model already has the useful pieces. Project memory is stored
as reviewable local files. memory load compiles a task-focused context pack.
Local MCP can expose memory tools for loading, searching, inspecting, saving,
and diffing memory when the client has launched and connected to memory-mcp.
The difference is subtle but important.
Without Memory, my project conversation often starts with a context dump:
Here is the product brief, the architecture summary, the agent instructions,
the latest decisions, the known gotchas, the setup commands, and the part of
the codebase I think matters.That is expensive, noisy, and easy to get wrong. It also nudges me to hand over more source than the conversation actually needs.
With Memory, I want the assistant to start from a smaller question:
What durable project memory is relevant to "plan the billing integration"?The answer should be a compact context pack: product intent, constraints, workflow notes, source records, known traps, and open questions that matter for that task.
For routine CLI use, I can get that pack directly:
memory load "plan the billing integration"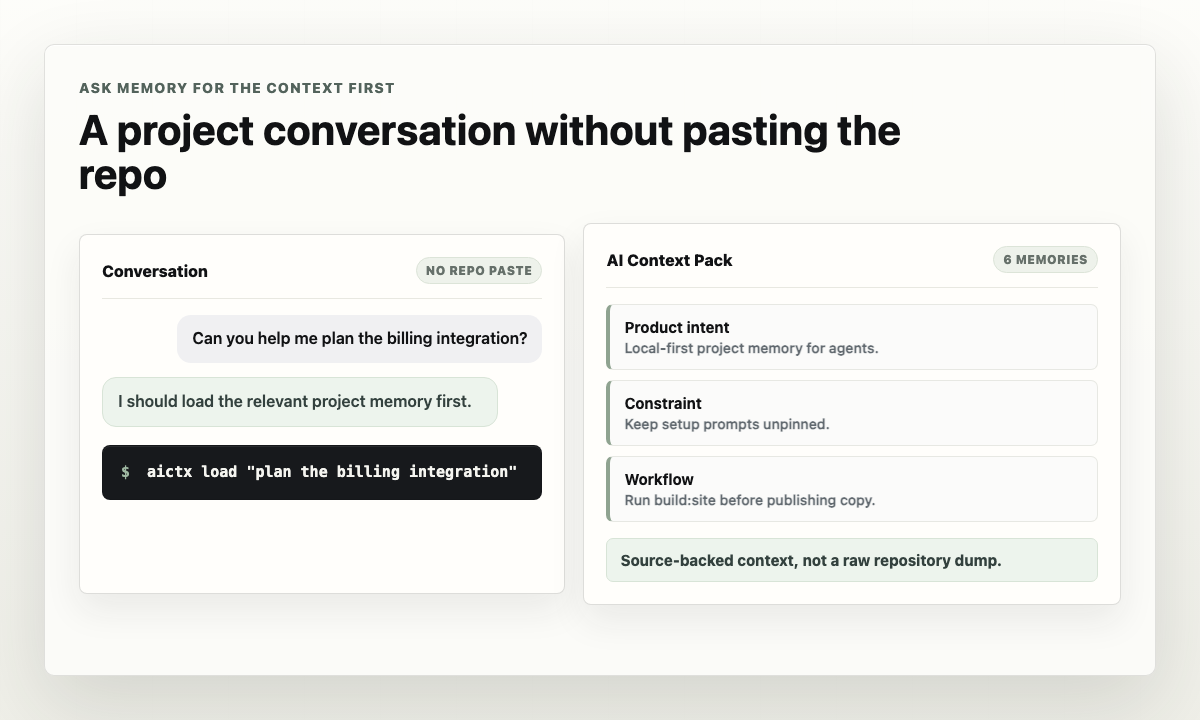
If the conversation needs more detail, the assistant can search or inspect memory objects instead of asking for the whole repository.
That does not mean Memory replaces code review or implementation access. Some tasks still need source files. But many conversations do not. Product planning, architecture discussion, onboarding, roadmap review, risk analysis, and handoff cleanup often need project knowledge more than raw code.
This is also why I keep the boundary clear between the current local workflow and future hosted surfaces. Today, the CLI is the default routine path, and local MCP is available when an MCP-capable client already exposes the Memory tools. Remote MCP endpoints, hosted sync, cloud auth, and ChatGPT App SDK UI are not the v1 promise.
The useful promise is narrower and stronger: project memory should be portable, local, inspectable, and shaped so different assistants can ask for the context they need.
In that world, ChatGPT does not need to become the place where my entire repo lives. It can become another client that talks to the project memory layer. I get a conversation that understands the project, while keeping source access explicit and proportional to the work.
That is the direction Memory is built for: not bigger prompts, but better project memory.